C语言学习一:数据类型
数据类型
整形
概念: 表示整数类型的数据
1 | int a = 123 ; |
①先向系统申请一片内存,取名为 a;②确定该内存大小为 4 字节(1 字节 byte = 8 位 bit);③把 123 转化为二进制存放在该内存中
-
介绍
-
整型在
32位系统以及64位系统中都占用4字节 -
取值范围
1
2
3
4$ getconf INT_MAX
2147483647
$ getconf INT_MIN
‐2147483648 -
-
整型的修饰符:
- short 短整型,用于修饰整型的尺寸变为原本的一半,减少内存的开支,缩小取值范围
- long 长整型,用于修饰整型的尺寸使其尺寸变大(取决与系统),增加内存开支,扩大取值范围
- long long 长长整型,用于修饰整型的尺寸使其尺寸变大(取决与系统),增加内存开支,扩大取值范围 (在64位系统中 long 与 long long 的大小一致)
- unsigned 无符号整型,用来修饰整型并去掉符号位,使得整型数据没有负数,可以提正整数的取值范围 (0 - 4294967295)
- 整型数据在二进制存储时最高位(第31位)表示符号位,如果为1 则表示负数反之则表示正数
-
整数的存储方式:
-
原码: 正整数是直接使用原码进行存储的,比如100这个正整数,则直接把100 转换成二进制直接存储。
100 --> 0000 0000 0000 0000 0000 0000 0110 0100 -
补码:负数则是使用补码来存储,补码 = 原码的绝对值取反+ 1,取反和加1时符号位都不变
比如-100:
1
2
3100 --> 1000 0000 0000 0000 0000 0000 0110 0100
取反-> 1111 1111 1111 1111 1111 1111 1001 1011
加1 --> 1111 1111 1111 1111 1111 1111 1001 1100
注:
取反和加1的最前面的数字 1 不改变,他为符号位,表示正负,0为正,1为负 -
-
溢出:
概念:当超过取值范围时则会变成相邻的最小值/最大值
-
整型输出:
1
2
3
4
5
6
7
8
9int c = 100;
printf("十六进制:%#x\n" , c); //`#` 是格式说明符的一部分
printf("十进制:%d\n" , c);
printf("八进制:%#o\n" , c);
// 输出结果:
十六进制:0x64
十进制:100
八进制:0144 -
sizeof 运算符
用于计算变量/类型的大小。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16int main()
{
int a=123;
printf("sizeof(short):%ld\n",sizeof(short));
printf("sizeof(int):%ld\n",sizeof(int));
printf("sizeof(long):%ld\n",sizeof(long));
printf("sizeof(long long):%ld\n",sizeof(long long));
}
//注意括号内部可以写变量类型, 也可以写变量名
//输出结果
sizeof(a):4
sizeof(short):2
sizeof(int):4
sizeof(long):8
sizeof(long long):8
在 32 位平台下,int 型和 long 型是一致的,都是占用 4 个字节。Long long 是 8 个字节。
在 64 位平台下,int 型是占用 4 个字节,而 long 和 long long 都是占用 8个字节的。
尽量不要使用 long 和 long int,因为 c/c++标准中,只限制了 long int 长度不小于 int,并未限制 long 必须是 4 个字节或者 8 个字节,也就是跟平台相关,这主要是因为有一些历史兼容性原因。所以要使用明确的 long long 或者 uint64_t
浮点型(实型):
- 介绍
- 概念:用来表达一个实数的数据类型
- 分类
- 单精度浮点型 float , 典型尺寸 4 字节
- 双精度浮点型 double , 典型尺寸 8 字节
- 长双精度 long double ,典型尺寸 16 字节
占用的内存越多则精度越高
-
浮点数的存储
- 虽然浮点数储存的也是
0,1,但和整形不一样 - 整形是原码补码储存
- 浮点型是通过计算得出的浮点数二进制码
IEEE 浮点标准采用如下形式来表示一个浮点数
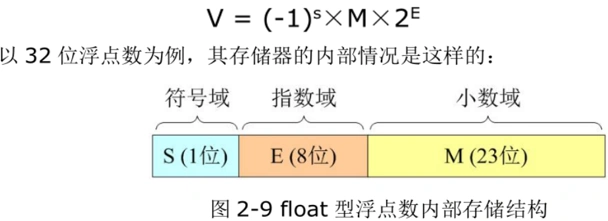
1
2
3float f = 3.14; // 浮点数3.14 通过以上公式计算得到的二进制码,存放在在内存f中
printf("f:%f\n",f); // 使用浮点的计算方法来解析内存f中的值(二进制)
printf("d:%d\n",f);// 直接使用整型的计算方法来直接解析内存f 中的值 (二进制)虽然所有的数据都会被转换成二进制进行存储,但如果想到的到正确的数据,必须使用正确的理解方式(类型),来解析二进制数据。所以不能用%d
- 虽然浮点数储存的也是
字符类型
字符
-
介绍
char c = 'K' ;
①申请一片内存并且命名为 c
②确定内存的大小为 char (1字节)
③把字符‘K’的 ASCII 码值转换为二进制,并存储到该内存中计算机中存储的所有数据都是以二进制的形式存在的,因此字符必须映射某一个数字才能
够被存放到计算机中,这个映射的表就成为 ASCII 表,可以使用 man 手册来查看man ascii字符之间的比较就是比较他们的 ASCII 码
点击查看 man ascii 解释
- oct(Octal): 这一列显示了 ASCII 字符的八进制(octal)表示。ASCII 字符可以用三位八进制数字表示,例如,大写字母’A’对应的八进制表示为101。
- dec(Decimal): 这一列显示了ASCII字符的十进制(decimal)表示。ASCII字符可以用十进制数字表示,例如,大写字母’A’对应的十进制表示为65。
- hex(Hexadecimal): 这一列显示了ASCII字符的十六进制(hexadecimal)表示。ASCII字符可以用两位十六进制数字表示,例如,大写字母’A’对应的十六进制表示为41。
- cher(Character): 这一列显示了对应的可打印字符或控制字符。可打印字符是可以显示在屏幕上的字符,如字母、数字和符号。控制字符是用于特殊控制目的的字符,如换行符(newline)和回车符(carriage return)。
例:
1
2
3char c = '1' ;
printf("字符:%c\n",c); // 以字符的形式来解析内存 c 的内容得到 对应的字符 1
printf("整型ASCII值:%d\n",c); //以十进制整型来解析内存c 的内容 ,得到1多对应的ASCII值 -
注意:
字符实质上是一个单字节的整型,因此支持所有整型的操作
1
2
3
4
5
6
7
8
9
10int main()
{
char k = 'H' ;
printf("k + 1: %c\n" , k + 1 );
printf("k - 1: %c\n" , k - 1 );
}
//输出结果
k + 1: I
k - 1: G
字符串
字符串的表现形式有两种:
-
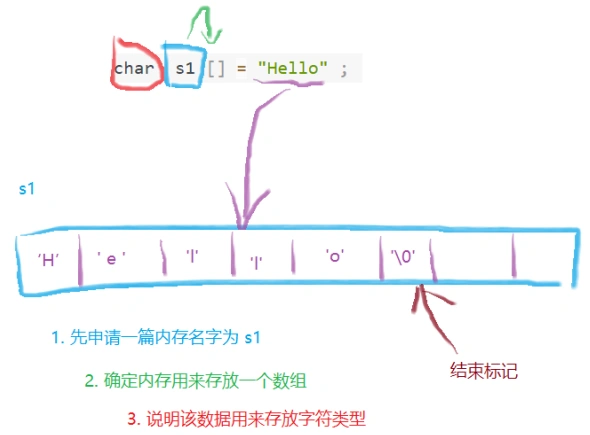
数组(可读,可写):(存储)
1
char s1[] = "Hello" ; //使用一个数组来存放字符串 "Hello"
以上语句其实是把一个字符串常量 “Hello” ,复制到数组 s1 所代表的内存当中
-
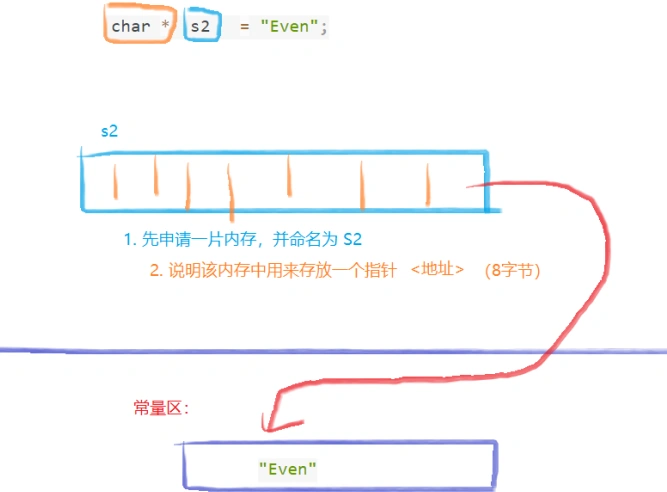
指针 (只读):(指向)
1
char *s2 = "Even"; // 使用一个指针来指向常量字符串
1
2
3
4
5
6
7
8
9int main()
{
char s1[] = "abc";
char *s2="def";
printf("%s %s\n",s1,s2);
}
//输出结果
abc def
布尔类型
概念: 布尔类型用来表示真/假 (非零则真)
真:true 假:false
注意在使用布尔类型是需要包含他的头文件: <stdbool.h>
1 | bool a = 1 ; // 真 |
一般布尔类型的变量,可以用于逻辑判断比如 if / while ,或者用于函数的返回值。
布尔类型的大小:
1 | bool a = true ; |
常量与变量
概念: 不可以被改变的内存,被称为常量,可以被改变的内存则成为变量
1 | int a = 100 ; // a是一个变量, 而 100 则是常量 |
常量类型:
- 100 :整型常量
- 100L : 长整型 long
- 100LL : 长长整型 long long
- 100UL : 无符号的长整型 unsigned long
- 3.14 : 编译器默认升级为双精度浮点型
- 3.14L : 长的双精度浮点型
- ‘a’ : 字符常量
- “Hello” : 字符串常量(指针 char * )
标准输入与标准输出(格式化输出)
标准输入
概念: 标准输入一般指的是键盘的设备文件,从键盘获取数据就成为标准输入
1 | scanf( ); // 扫描键盘 (格式化输入数据 ‐‐> 从键盘中获得指定类型的数据) |
补充:
1 | char * p = malloc(32); // p是指针,使用 p 而不是 &p,因为 p 就是一个地址 |
实例:
1 | int main(int argc, char const *argv[]) |
注:如果以后需要从标准输入中获取数据得到乱码或未知数据,则可以尝试使用 getchar 进行清空再获取。
标准输出(格式化输出)
概念:屏幕(终端)对应的就是标准输出的设备文件,如果往该文件中输出内容则可以成为标准输出。
printf( );
-
注意语法点
%必须有的,格式化的开头标记- 对齐的方式, 向左对齐(空格在右) ,如果没有则是向右对齐(空格在左)
m.nm 指的域宽(需要的字符数), n 指的是精度(默认精度为6)
m 的值如果比实际数据小则按实际输出,反之则用空格来填补l指的是 long 表示长整型h指的是短整型
-
格式控制符
- 十进制的整型:
%d%md%ld%u(无符号)%lu - 八进制:
%o%#o# --> 输出进制的符号 - 十六进制:
%x%#x%#X - 字符:
%c - 字符串:
%s - 单精度浮点:
%f%.nf--> n 表示精度 - 双精度:
%lf - 长双精度 :
%Lf - 地址:
%p
1
2
3printf("%d\n" , 0123 ); // 使用十进制的格式来输出一个八进制数据 0123 ‐‐>83
printf("%o\n" , 0123 ); // 使用八进制的格式来输出一个八进制数据 0123 ‐‐>123 - 十进制的整型:
类型的转换
概念:不同的数据类型但是可以兼容的类型之间,如果出现在同一表达式中则会发生类型的转换。
-
隐式转换(自动)
若在表达式中用户没有手动进行转换,则系统会自动转为高精度的类型(由低精度转换为高精度)
比如: float + double + int --> 则系统会自动全部转为 double -
强制转换(手动)
用户根据自己的需求进行强制的类型转换 ( int )a --> 强制性把 a 转换为整型
注意:不管是隐式转换还是强制转换,准换的只是在运算的过程中,并不会影响到原本的数,这是一个临时的转换。
运算中可能会丢失精度,但不会影响数据本来的值,只是临时转换
例如:
1
2
3
4
5
6
7
8
9
10
11
12int main()
{
int a=100;
char c='k';
float f=3.14;
double d=998526.153;
//只是临时转换高精度的double m, a、c、f、d实际没变
double m=a+c+f+d; //隐式转换
int n=(int)a+(int)c+(int)f+(int)d; //强制转换
printf("m= %lf,n=%d\n",m,n);
}
精度排序:
char:1个字节。通常用于存储字符和小整数值。short:2个字节。通常用于较小的整数值。int:4个字节。通常用于一般整数值。float:4个字节。单精度浮点数,通常用于存储小数值,具有较高的精度。double:8个字节。双精度浮点数,通常用于存储双精度小数值,具有更高的精度。long double:这个数据类型的大小可以因系统而异,通常为8个字节或更多。它提供了比double更高的精度,适用于需要更高精度的计算
补充
数据类型的本质:
-
概念:
各种不同的数据类型,从本质上是用户与系统之间的一个约定,这个约定用来如何正确的解析内存中的二进制编码。
比如整形使用原码补码,浮点型是通过计算得出的浮点数二进制码
-
推论:
类型转换:实际上就是在临时打破之前的约定。
理论上任何的数据都可以进行转换,但是转换之后是否有意义?
整型的尺寸
-
概念:尺寸指的是某一个数据需要多少内存来存储(占用的内存空间)
在 C 语言中并没有规定某一个数据类型他的尺寸是多少,但是有个相对的大小约定
Short 不可能比 int 长
Long 不可能比 int 短
Long 的长度等于系统的字长(系统位数,比如 32 位,64 位)如何查看系统字长:有很多方法
1
2
3
4
5
6//方法一,终端输入
$ getconf LONG_BIT
64
//方法二,终端输入
$ uname -a -
典型尺寸:
- char 占用 1 个字节
- short 占用 2个字节
- int 占用 4 个字节
- long 占用 4(32 位系统) / 8(64 位系统) 个字节
可移植类型
相同的代码在不同(位数)的系统中,它所占用的尺寸会发生变化,有可能导致数据的精度出现问题,严重的可能会导致程序无法运行。
因此,系统中会提供一些可移植类型。
概念:不管在什么系统中,数据的尺寸都是固定不会发生变化的数据类型,称为可移植数据类型
关键词:typedef
1 | typedef int zzz; //相对于用typedef给int取个别名为zzz |
系统提供了一些预定义的
通过 cd /usr/include 后,运行 find -name types.h 会发现./x86_64-linux-gnu/bits/types.h
路径:/usr/include/x86_64-linux-gnu/bits/types.h
1 | /* Convenience types. */ |





